系統整合的藝術:API、Event、Data 三大整合模式
本篇是「雲端架構設計基礎」系列的第 1 / 1 篇。你可以從系列總覽開始閱讀,也可以直接接著看本文。
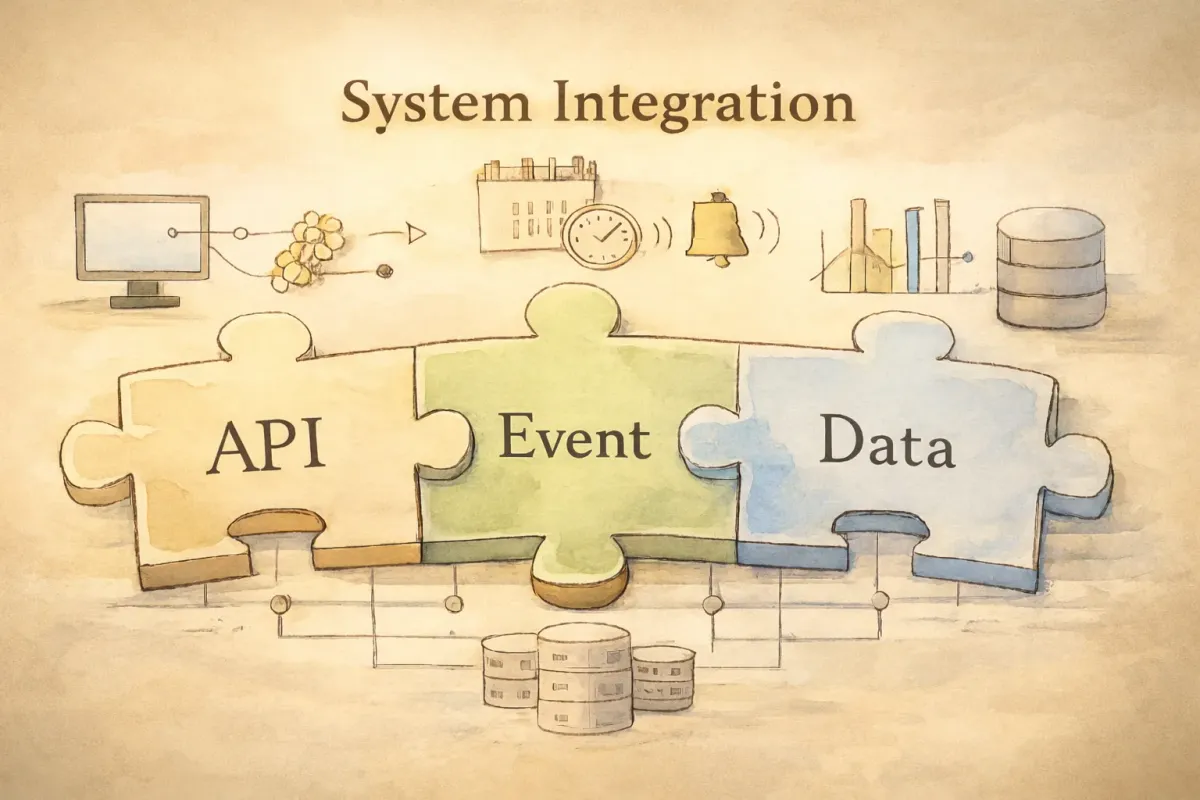
在現代雲端架構中,系統整合是決定架構成敗的關鍵因素。2023 年,一個知名旅遊平台因為系統整合出錯,導致訂單重複扣款,損失數百萬元——這就是整合失誤的代價。本文將帶你深入了解三大整合模式:API 整合、Event-Driven 架構、Data 整合,並學習如何在實務中做出正確選擇。
目錄
- 概述
- Step 1: 為什麼系統整合如此重要?
- Step 2: 整合模式 1:API 整合
- Step 3: 整合模式 2:Event-Driven
- Step 4: 整合模式 3:Data 整合
- Step 5: 混合雲與遺留系統整合
- Step 6: 整合的最佳實踐
- Step 7: 總結與選擇指南
- 學到的內容
- 下一步
概述
現代系統不再是單一巨石應用,而是由微服務、雲端服務、SaaS 組成的分散式架構。一個電商平台可能需要整合支付系統 (Stripe)、物流系統 (順豐)、庫存 ERP、客戶關係管理 (Salesforce)——這麼多系統要串起來,選錯整合方式就會踩雷。
本文將帶你了解 API、Event、Data 三大整合模式的核心概念、技術選型、適用場景,並提供實務決策指南。無論你是後端開發者、系統架構師,還是雲端架構初學者,都能從中獲得實用的整合策略。
Step 1: 為什麼系統整合如此重要?
單體應用已死,分散式成為常態
過去的應用是單一巨石 (Monolith),所有功能都在一個程式碼庫、一個資料庫中。但隨著業務複雜度提升,單體應用變得難以維護、難以擴展、部署風險高。現在,微服務、雲端服務、SaaS 成為主流架構模式。
這種轉變帶來新的挑戰:如何讓這些分散的系統協同運作? 答案就是系統整合。
真實事故:整合失誤的代價
2023 年,一個旅遊平台因為系統整合出錯,導致訂單重複扣款。問題的根源是缺乏冪等性 (Idempotency) 設計——當用戶重試支付請求時,系統無法識別這是重複請求,導致同一筆訂單被扣款多次。最終,平台損失數百萬元,用戶體驗嚴重受損。
這個案例告訴我們:整合不只是技術問題,更是業務風險問題。 選擇正確的整合模式、應用最佳實踐,是系統成功的關鍵。
電商平台的整合挑戰
以電商平台為例,需要整合:
- 支付系統 (Stripe, PayPal):處理金流
- 物流系統 (順豐, UPS):追蹤訂單配送
- 庫存 ERP:即時更新庫存
- CRM (Salesforce):管理客戶關係
- 推薦系統:個人化商品推薦
如果採用緊耦合的整合方式 (如直接呼叫),當物流系統故障時,整個訂單流程可能被阻塞。採用鬆耦合的事件驅動架構,則可以確保系統的可用性和可擴展性。
重點整理
- 分散式系統是常態:微服務、雲端服務、SaaS 成為主流
- 整合失誤代價高:2023 年旅遊平台訂單重複事故損失數百萬
- 選擇正確模式是關鍵:API、Event、Data 各有適用場景
- 電商整合挑戰:需整合支付、物流、庫存、CRM 等多個系統
Step 2: 整合模式 1:API 整合
API 整合的三大流派
API 整合是最常見的同步整合模式,透過 HTTP 協議交換資料。現代 API 技術主要有三大流派:RESTful API、GraphQL、gRPC。
RESTful API:資源導向、簡單易懂
RESTful API 是最成熟的 API 技術,採用資源導向 (Resource-Oriented) 設計:
- HTTP 動詞:GET (讀取)、POST (新增)、PUT (更新)、DELETE (刪除)
- 無狀態:每個請求包含完整的上下文,不依賴伺服器狀態
- 資料格式:JSON 或 XML
- 適用場景:CRUD 操作、公開 API、簡單易懂的介面
範例:
GET /api/users/123
Response:
{
"id": 123,
"name": "Alice",
"email": "alice@example.com"
}優點:
- 簡單易懂,學習曲線低
- 工具成熟,廣泛支援
- 適合公開 API
缺點:
- Over-fetching (拿到不需要的資料)
- Under-fetching (需要多次請求才能取得完整資料)
GraphQL:客戶端定義查詢、精確資料獲取
GraphQL 讓客戶端自己定義需要什麼資料,伺服器回傳精確符合需求的資料:
- 單一端點:所有查詢都透過同一個端點
- 精確資料獲取:減少 over-fetching 和 under-fetching
- 型別安全:強型別 schema 定義
- 適用場景:Mobile App、SaaS 儀表板、需要靈活查詢的應用
範例:
query {
user(id: 123) {
name
email
}
}優點:
- 減少網路請求次數
- 客戶端靈活性高
- 強型別,減少錯誤
缺點:
- 學習曲線較陡
- 伺服器端實作複雜
- 快取較困難
gRPC:高效能、二進位協議
gRPC 是 Google 開發的高效能 RPC 框架:
- 二進位協議:使用 Protocol Buffers (Protobuf),比 JSON 小 3-10 倍
- HTTP/2:支援雙向串流、多路複用
- 強型別:透過 .proto 檔案定義介面
- 適用場景:內部微服務、即時通訊、低延遲要求
優點:
- 效能極高,適合高吞吐場景
- 支援雙向串流
- 強型別,減少錯誤
缺點:
- 學習曲線最陡
- 除錯較困難 (二進位格式)
- 瀏覽器支援有限
API 設計原則
無論選擇哪種 API 技術,都應遵循以下設計原則:
-
版本控制:
- URL 版本:
/api/v1/users - Header 版本:
Accept: application/vnd.api+json; version=1
- URL 版本:
-
錯誤處理:
- 使用正確的 HTTP Status Code (200, 404, 500)
- 回傳結構化錯誤訊息
-
速率限制 (Rate Limiting):
- 防止濫用,保護伺服器
- 使用
X-RateLimit-Limitheader 告知限制
-
文件化:
- 使用 Swagger/OpenAPI 自動生成文件
- 提供範例和錯誤碼說明
API Gateway 模式
在微服務架構中,API Gateway 扮演統一入口的角色:
- 統一入口:所有外部請求先經過 API Gateway
- 身份驗證:集中處理 OAuth、JWT 驗證
- 速率限制:保護後端服務
- 監控與日誌:統一收集請求日誌
- 負載平衡:分散流量到多個後端服務
工具範例:
- Kong:開源、Plugin 生態豐富
- AWS API Gateway:雲端託管、與 AWS 服務整合
- Azure API Management:企業級、支援混合雲
2025 混合策略
現代系統不再只使用單一 API 技術,而是根據場景混合使用:
- 簡單場景:REST (如公開 API、CRUD 操作)
- 需要靈活性:GraphQL (如 Mobile App、SaaS 儀表板)
- 要求效能:gRPC (如內部微服務、即時通訊)
重點整理
- RESTful API:資源導向、簡單易懂、適合 CRUD
- GraphQL:客戶端定義查詢、減少網路請求、適合 Mobile App
- gRPC:高效能、二進位協議、適合內部微服務
- API Gateway:統一入口、身份驗證、速率限制 (工具:Kong、AWS API Gateway)
- 混合策略:根據場景選擇 REST、GraphQL、gRPC
Step 3: 整合模式 2:Event-Driven
Event-Driven Architecture (EDA) 是什麼?
Event-Driven Architecture (事件驅動架構) 是一種非同步整合模式,服務間透過事件 (Event) 溝通,而非直接呼叫。
想像一個電商下單流程:
- 傳統做法:訂單系統直接呼叫庫存系統、金流系統、物流系統
- 事件驅動:訂單系統發出「訂單成立」事件,其他系統自己訂閱這個事件來處理
這就是 Pub/Sub (發布/訂閱) 模式:發布者發事件、訂閱者接事件,完全解耦。
Pub/Sub 模式
Pub/Sub 模式包含三個角色:
- 發布者 (Publisher):發出事件
- 主題 (Topic):事件的分類
- 訂閱者 (Subscriber):接收並處理事件
優點:
- 解耦:發布者不需要知道誰在訂閱
- 一對多:一個事件可以被多個訂閱者處理
- 非同步:發布者不需要等待訂閱者完成
Message Queue:Kafka vs RabbitMQ
實作 Event-Driven 架構需要 Message Queue (訊息佇列) 工具:
Kafka:吞吐量怪獸
- 超高吞吐量:每秒可處理超過 100 萬則訊息
- 持久化:訊息持久化到磁碟,可重播
- Event Sourcing:將所有狀態變更儲存為事件序列
- 2025 更新:KRaft 模式取代 ZooKeeper,單一二進位部署,大幅簡化運維
- 適用場景:大數據處理、Event Sourcing、需要重播歷史事件
挑戰:
- 運維成本高:需要專職團隊維護
- 學習曲線陡:概念複雜 (Partition, Offset, Consumer Group)
RabbitMQ:靈活易用
- 靈活路由:支援多種路由模式 (Direct, Topic, Fanout, Headers)
- 訊息確認:確保訊息不遺失 (Acknowledgement)
- 易於設置:中小團隊也能輕鬆上手
- 適用場景:交易處理、需要訊息確認、中小型團隊
挑戰:
- 吞吐量較低:相比 Kafka,適合中小流量
- 不支援重播:訊息消費後即刪除
如何選擇?
| 需求 | 選擇 |
|---|---|
| 吞吐量 > 10萬 msg/s | Kafka |
| 需要重播歷史事件 | Kafka |
| 團隊規模 < 10 人 | RabbitMQ |
| 需要交易確認 | RabbitMQ |
| 雲端託管,無需管理 | AWS SQS |
Event Sourcing 與 CQRS
Event Sourcing
將所有狀態變更儲存為事件序列,而非只儲存最終狀態:
- 完整審計日誌:可追溯所有變更
- 時間旅行:可重播到任意時間點的狀態
- 除錯友善:可看到完整事件流
範例:銀行帳戶
- 傳統做法:只儲存最終餘額 (如 1000 元)
- Event Sourcing:儲存所有交易事件 (存款 +500, 提款 -200, …)
CQRS (Command Query Responsibility Segregation)
分離寫入和讀取模型:
- Command Model:處理寫入操作
- Query Model:處理讀取操作
優點:
- 寫入和讀取可獨立擴展
- 查詢模型可針對特定場景優化
Event-Driven 的優缺點
優點:
- 解耦:服務間無直接依賴
- 非同步:不阻塞主流程
- 可擴展:新增訂閱者無需修改發布者
- 容錯:一個服務失敗不影響其他服務
缺點:
- 複雜度高:分散式追蹤困難
- 除錯困難:事件流向難以追蹤
- 最終一致性:無法保證強一致性
適用場景
- 訂單處理流程:訂單成立 → 庫存扣減 → 金流處理 → 物流通知
- 庫存更新通知:庫存變更 → 推薦系統更新 → 前端即時顯示
- 使用者行為追蹤:點擊事件 → 分析系統 → 推薦模型
- IoT 資料串流:感測器資料 → 即時分析 → 告警系統
Dead Letter Queue (DLQ)
處理失敗訊息的機制:
- 當訊息處理失敗超過重試次數,移至 DLQ
- 定期檢查 DLQ,分析失敗原因
- 修正問題後,重新處理 DLQ 中的訊息
重點整理
- Pub/Sub 模式:發布者 → 主題 → 訂閱者,完全解耦
- Kafka:吞吐量 > 100萬 msg/s、Event Sourcing、需專職團隊
- RabbitMQ:靈活路由、易於設置、中小團隊可維護
- Event Sourcing:儲存所有事件、完整審計日誌、時間旅行
- 優點:解耦、非同步、可擴展;缺點:複雜、除錯難、最終一致性
- 適用場景:訂單處理、庫存更新、使用者行為追蹤、IoT 資料串流
Step 4: 整合模式 3:Data 整合
Data 整合的三大策略
Data 整合處理大量資料的搬移和轉換,主要有三大策略:ETL、ELT、CDC。
ETL (Extract, Transform, Load)
傳統批次處理方式:
- Extract (提取):從來源系統提取資料
- Transform (轉換):清洗、轉換資料格式
- Load (載入):載入目標系統
適用場景:
- 定期報表 (如每日、每週)
- 資料清洗優先
- 傳統 BI 系統
優點:
- 資料品質高 (先清洗後載入)
- 邏輯集中,易於管理
缺點:
- 轉換過程慢
- 無法即時處理
ELT (Extract, Load, Transform)
雲端時代的新趨勢:
- Extract (提取):從來源系統提取資料
- Load (載入):直接載入目標系統
- Transform (轉換):在目標系統中轉換
為什麼這樣做? 因為像 BigQuery、Snowflake 這些雲端資料倉儲算力超強,讓它們去轉換資料更有效率。
適用場景:
- 雲端資料倉儲 (BigQuery, Snowflake)
- 大數據處理
- 需要彈性查詢
優點:
- 快速載入,即時可查
- 利用目標系統的算力
缺點:
- 資料品質檢查延後
- 目標系統資源消耗大
CDC (Change Data Capture)
2025 年的趨勢,只追蹤資料變更:
- 變更捕獲:僅追蹤新增、修改、刪除的資料
- 即時同步:近即時或即時同步
- 節省資源:只傳輸變更,而非全量資料
適用場景:
- 資料庫複製
- 微服務資料同步
- 即時分析
- 詐欺偵測
優點:
- 即時性高
- 資源消耗低
- 支援漸進式遷移
CDC 工具選擇
| 工具 | 類型 | 適用場景 |
|---|---|---|
| Debezium | 開源 | 預算有限、需要客製化 |
| Fivetran | 商業、全託管 | 需要穩定、無需維護 |
| Airbyte | 開源友善 | 平衡點、社群活躍 |
選擇建議:
- 預算有限:Debezium (開源)
- 需要全託管:Fivetran (商業)
- 要平衡點:Airbyte (開源友善)
Data Lake vs Data Warehouse
Data Lake (資料湖):
- 儲存原始資料 (Raw Data)
- Schema-on-Read:讀取時才定義 schema
- 適合大數據、非結構化資料
Data Warehouse (資料倉儲):
- 儲存結構化資料
- Schema-on-Write:寫入時定義 schema
- 適合 BI、報表、分析
Stream Processing
即時資料處理,而非批次處理:
- Apache Flink:強大的即時處理引擎
- Kafka Streams:輕量級,與 Kafka 整合
適用場景:
- 即時推薦
- 詐欺偵測
- 即時儀表板
2025 趨勢:CDC 取代 ETL
CDC 正在取代傳統批次 ETL,成為即時整合的首選:
- 即時性:從每日批次 → 即時同步
- 成本低:只傳輸變更,節省資源
- 靈活性:支援漸進式遷移
組合方法
實務上,CDC 常與 ETL/ELT 管道結合:
- CDC 捕獲變更
- ETL/ELT 管道 處理和分析
重點整理
- ETL:先轉換後載入、適合定期報表、資料品質高
- ELT:先載入後轉換、利用雲端算力、適合大數據
- CDC:只追蹤變更、即時同步、節省資源
- 工具選擇:Debezium (開源)、Fivetran (全託管)、Airbyte (平衡)
- 2025 趨勢:CDC 取代傳統批次 ETL
Step 5: 混合雲與遺留系統整合
現實世界的挑戰:遺留系統
許多企業面臨一個問題:如何整合那些跑了幾十年的老古董 COBOL 系統?直接重寫風險太高,但又需要現代化。
答案是:Strangler Fig Pattern (絞殺榕模式)。
Strangler Fig Pattern
由 Martin Fowler 提出,靈感來自絞殺榕:一種植物慢慢纏繞並取代老樹。
運作機制:
- 代理層 (Proxy) 攔截請求:所有請求先經過代理層
- 路由到新舊系統:新功能路由到新系統、舊功能保留在舊系統
- 增量替換:逐步將功能從舊系統遷移到新系統
- 最終移除:當所有功能遷移完成,移除舊系統
優點:
- 降低風險:逐步遷移,而非大爆炸式重寫
- 獨立測試:每個功能可獨立測試
- 可回滾:遷移出問題可立即回滾
- 立即獲得收益:新功能上線即可使用
挑戰與應對策略
挑戰 1:代理層單點故障
問題:代理層掛掉,整個系統掛掉
應對:使用 HA (High Availability) 設計
- 部署多個代理層實例
- 使用負載平衡器
- 設定健康檢查和自動故障轉移
挑戰 2:資料同步複雜
問題:新舊系統需要同步資料
應對:雙寫策略 + 最終一致性
- 雙寫:同時寫入新舊系統
- 最終一致性:接受短暫的資料不一致
- Feature Toggle:逐步切換流量
其他整合模式
API Facade
包裝遺留系統為現代 REST/gRPC API:
- 隱藏複雜性:遺留系統的複雜介面被包裝成簡單 API
- 漸進式遷移:可逐步替換背後的實作
Database Gateway
資料庫層級整合:
- 雙寫策略:同時寫入新舊資料庫
- 資料同步:定期同步資料
Adapter Pattern
協議轉換:
- SOAP → REST:將舊 SOAP API 轉換為 REST API
- 舊 API → 新 API:適配器模式
Integration Hub / ESB
企業服務匯流排 (Enterprise Service Bus):
- 集中管理:所有整合邏輯集中在 ESB
- 避免單點故障:確保 ESB 本身的高可用性
實際案例
銀行核心系統現代化
許多銀行使用 Strangler Fig Pattern 從 COBOL 遷移到微服務:
- 代理層:新增 API Gateway 攔截所有請求
- 新服務:用 Java/Go 重寫新功能
- 雙寫:同時寫入 COBOL 和新資料庫
- 逐步切換:用 Feature Toggle 逐步切換流量
- 最終移除:當所有功能遷移完成,移除 COBOL
電商從單體遷移到 K8s
- 容器化:將單體應用容器化
- 拆分服務:逐步拆分成微服務
- Kubernetes 部署:遷移到 K8s
- Service Mesh:使用 Istio 管理服務間通訊
重點整理
- Strangler Fig Pattern:逐步取代遺留系統,降低風險
- 代理層 HA:避免單點故障
- 雙寫策略:同時寫入新舊系統,最終一致性
- API Facade:包裝遺留系統為現代 API
- 實際案例:銀行 COBOL → 微服務、電商單體 → K8s
Step 6: 整合的最佳實踐
學完三大整合模式,還要知道三大彈性模式,確保系統不會掛掉!
Idempotency (冪等性)
定義:多次執行操作與執行一次具有相同效果。
生活化比喻:按電梯按鈕,按一次和按十次結果一樣。
為什麼重要? 在分散式系統中,網路可能會重試請求,如果沒有冪等性設計,可能導致:
- 訂單重複 (2023 年旅遊平台事故)
- 重複扣款
- 資料不一致
實作方式:使用唯一 ID (Request ID)
// 伺服器端檢查重複請求
function processPayment(requestId, amount) {
// 檢查 requestId 是否已處理過
if (processedRequests.has(requestId)) {
return { status: 'already_processed' };
}
// 處理付款
charge(amount);
// 記錄 requestId
processedRequests.add(requestId);
return { status: 'success' };
}Circuit Breaker (斷路器)
定義:防止級聯失敗,像家裡的保險絲。
狀態機:
- Closed (正常):請求正常通過
- Open (切斷):當下游服務故障,自動切斷請求
- Half-Open (測試恢復):定期測試下游服務是否恢復
為什麼重要? 當下游服務故障時,避免整個系統跟著掛掉。
實作範例:
class CircuitBreaker {
constructor(threshold = 5, timeout = 60000) {
this.failureCount = 0;
this.threshold = threshold;
this.timeout = timeout;
this.state = 'CLOSED';
}
async call(fn) {
if (this.state === 'OPEN') {
throw new Error('Circuit breaker is OPEN');
}
try {
const result = await fn();
this.onSuccess();
return result;
} catch (error) {
this.onFailure();
throw error;
}
}
onSuccess() {
this.failureCount = 0;
this.state = 'CLOSED';
}
onFailure() {
this.failureCount++;
if (this.failureCount >= this.threshold) {
this.state = 'OPEN';
setTimeout(() => {
this.state = 'HALF_OPEN';
}, this.timeout);
}
}
}Retry Strategies (重試策略)
三種重試策略:
- 立即重試:立即重試,適合短暫故障
- 延遲重試:等待固定時間後重試
- 指數退避 (Exponential Backoff):每次等待時間翻倍
加入抖動 (Jitter):在等待時間中加入隨機性,避免重試風暴。
範例:
async function retryWithExponentialBackoff(fn, maxRetries = 3) {
for (let i = 0; i < maxRetries; i++) {
try {
return await fn();
} catch (error) {
if (i === maxRetries - 1) throw error;
// 指數退避 + 抖動
const delay = Math.pow(2, i) * 1000 + Math.random() * 1000;
await sleep(delay);
}
}
}Timeout Settings (超時設定)
層級設定:
- 連線超時 (Connection Timeout):建立連線的最大時間
- 讀取超時 (Read Timeout):讀取資料的最大時間
- 總超時 (Total Timeout):整個請求的最大時間
為什麼重要? 避免無限等待,確保請求最終會失敗或成功。
三者協同運作
- Idempotency 使 Retry 安全
- Circuit Breaker 阻止無效 Retry
- Retry + Idempotency = Exactly-Once 語義
監控與可觀測性
OpenTelemetry:統一標準
OpenTelemetry 是統一的可觀測性標準,包含:
- Trace:分散式追蹤,串聯 A→B→C 服務的請求路徑
- Metrics:指標監控 (如請求數、錯誤率)
- Logs:日誌聚合
範例:透過 Trace ID 串聯服務
Request ID: abc-123
Service A (處理時間 50ms) → Trace ID: abc-123
↓
Service B (處理時間 120ms) → Trace ID: abc-123
↓
Service C (處理時間 80ms) → Trace ID: abc-123透過 Trace ID abc-123,可以串聯 A→B→C 的完整請求路徑,一眼看出哪個服務慢。
ELK/Loki:日誌聚合
- ELK:Elasticsearch + Logstash + Kibana
- Loki:Grafana 推出的輕量級日誌系統
Prometheus:指標監控
- 收集指標 (Metrics)
- 支援強大的查詢語言 (PromQL)
- 與 Grafana 整合,視覺化儀表板
2025 見解:AI 驅動的彈性
- 動態調整重試參數:根據歷史資料動態調整重試次數
- 預測性斷路器:預測下游服務即將故障,提前切斷
錯誤處理
- Dead Letter Queue:處理失敗訊息
- 錯誤分類:Transient (暫時性) vs Permanent (永久性)
- 告警機制:設定告警閾值,及時發現問題
重點整理
- Idempotency:用 Request ID 檢查重複請求,讓重試安全
- Circuit Breaker:Closed → Open → Half-Open,防止級聯失敗
- Retry Strategies:指數退避 + Jitter,避免重試風暴
- 三者協同:Idempotency + Circuit Breaker + Retry = Exactly-Once
- OpenTelemetry:Trace ID 串聯 A→B→C 服務,分散式追蹤
Step 7: 總結與選擇指南
如何選擇整合模式?
根據以下 5 個問題做決策:
問題 1:是否需要即時回應?
- 是 → 選擇 API 整合
- RESTful API (簡單場景)
- GraphQL (需要靈活查詢)
- gRPC (要求效能)
- 否 → 選擇 Event 或 Data
問題 2:資料量是否巨大?
- 是 → 選擇 Data 整合
- ETL (傳統 BI)
- ELT (雲端資料倉儲)
- CDC (即時同步)
- 否 → 選擇 API 或 Event
問題 3:是否需要服務解耦?
- 是 → 選擇 Event-Driven
- Kafka (高吞吐量)
- RabbitMQ (中小團隊)
- 否 → 選擇 API
問題 4:是否需要歷史重播?
- 是 → 選擇 Kafka Event Sourcing
- 否 → 選擇 RabbitMQ 或其他
問題 5:有遺留系統需要整合嗎?
- 是 → 使用 Strangler Fig Pattern
- 代理層 + HA 設計
- 雙寫策略 + 最終一致性
混合使用範例:電商系統
真實世界的系統通常混合使用多種整合模式:
- REST API:前端查詢商品、使用者資訊
- Kafka:處理訂單流程 (訂單成立 → 庫存扣減 → 金流處理 → 物流通知)
- RabbitMQ:處理付款 (需要確認機制)
- CDC:同步庫存資料到資料倉儲
選擇整合模式的 Checklist
在實際專案中,使用以下 Checklist 做決策:
- 需要即時回應嗎? (API)
- 需要處理大量資料嗎? (Data)
- 需要服務解耦嗎? (Event)
- 有遺留系統需要整合嗎? (Strangler Fig)
- 需要可靠性保證嗎? (Idempotency + Circuit Breaker + Retry)
下一集預告
下一集我們要聊 Workload Disposition:Build、Buy、Modify 還是 Deprecate? 教你做出正確的雲端遷移決策。
記得訂閱我們的系列,我們下次見!
學到的內容
學習成果
-
理解 3 大整合模式的差異與適用場景
- API 整合:同步、即時回應
- Event-Driven:非同步、解耦
- Data 整合:批次或即時資料移動
-
掌握 RESTful API vs. GraphQL vs. gRPC 的選擇標準
- REST:簡單易懂、適合 CRUD
- GraphQL:靈活查詢、減少網路請求
- gRPC:高效能、適合內部微服務
-
學會 Event-Driven Architecture 的核心概念與工具選擇
- Kafka:高吞吐量、Event Sourcing
- RabbitMQ:靈活路由、易於設置
-
了解 ETL/ELT/CDC 的資料整合策略
- ETL:先轉換後載入
- ELT:先載入後轉換
- CDC:只追蹤變更、即時同步
-
識別遺留系統整合的漸進式策略 (Strangler Fig Pattern)
- 代理層 + HA 設計
- 雙寫策略 + 最終一致性
-
避免常見整合陷阱,應用最佳實踐
- Idempotency:用 Request ID 讓重試安全
- Circuit Breaker:防止級聯失敗
- Retry:指數退避 + Jitter
下一步
延伸學習資源
-
深入學習 API 設計
-
Event-Driven 架構
-
資料整合
-
最佳實踐
實作練習
- 建立 RESTful API:用 Express.js 或 FastAPI 建立簡單的 RESTful API
- 實作 Pub/Sub:用 RabbitMQ 實作簡單的訂單處理流程
- 應用 Circuit Breaker:在專案中實作斷路器模式
- 設定 OpenTelemetry:在微服務中加入分散式追蹤
相關課程
本文由 CloudOn 登雲學院 撰寫