為什麼我把所得地圖色階從 viridis 換成 OrRd:把「一個決策」拆成「兩個獨立軸」
本篇是「打造 TaxMap-TW:用 Astro 做台灣所得地圖」系列的第 8 / 10 篇。你可以從系列總覽開始閱讀,也可以直接接著看本文。
做 TaxMap-TW 兩週,色階換了三次:YlGnBu → viridis → OrRd。最後選 OrRd 不是因為「比較好看」,而是因為我把「一個決策」拆成了「兩個獨立軸」。
之前寫過一篇選 YlGnBu 的理由(系列第 1 篇 《資料地圖該用哪種色階?》),結論在實際做下來被自己推翻了。這篇是那篇的下一章。
背景:7,747 個村里的所得色階怎麼選
TaxMap-TW 是全台 7,747 個村里、11 年 × 4 指標可切換的所得熱度地圖。每個 polygon 要根據選定的年度與指標上色,選色階時我一開始把它當成「挑色卡」的問題:
- 第 1 次選 YlGnBu(淺黃 → 深藍):理由是「ColorBrewer 業界標準、色盲友善、公部門感」
- 第 2 次換 viridis(紫 → 藍 → 綠 → 黃):聽說 matplotlib 標準、感知均勻最科學
- 第 3 次定案 OrRd(淺米 → 深紅):使用者一句「viridis 不好看」之後重新思考
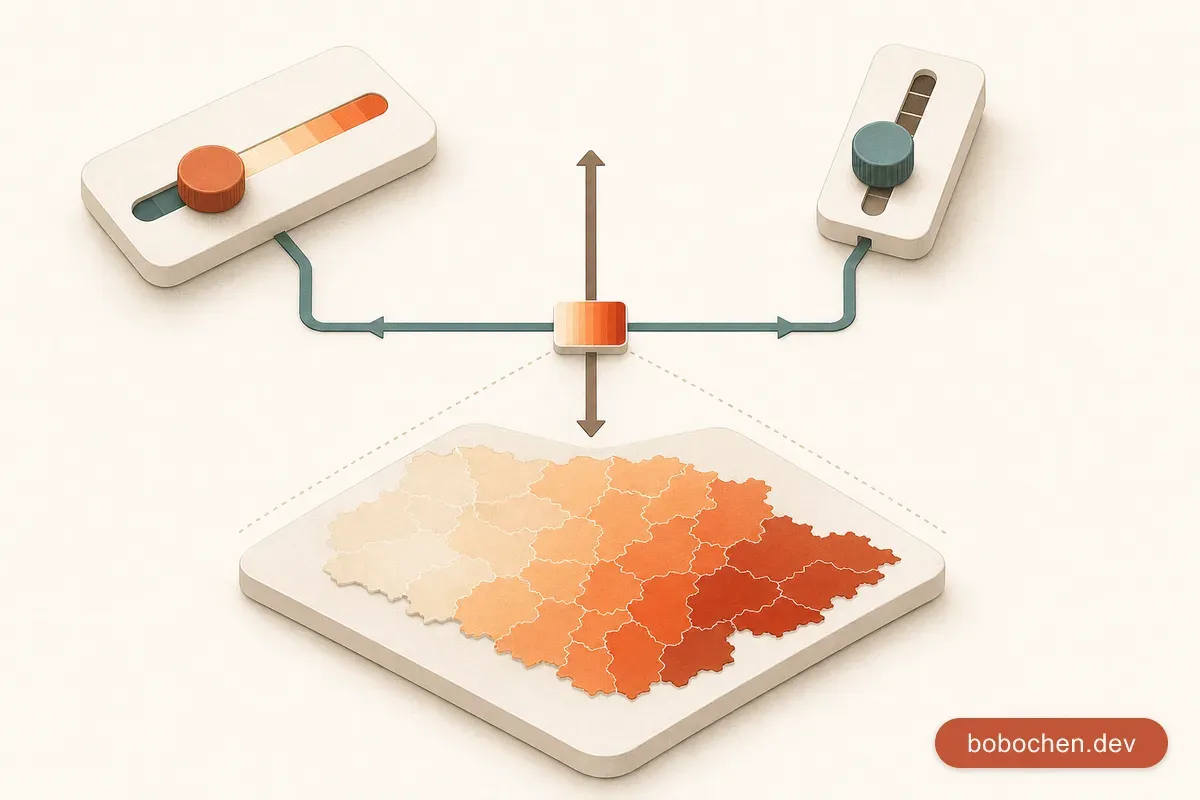
問題不在於哪一個「比較對」,而是我一直把「色階」當成單一決策。
發現過程
viridis 被打臉的那一刻
從 YlGnBu 換到 viridis 的理由很學術:
- Perceptually uniform(明度線性變化)
- 色盲友善(Daltonization safe)
- matplotlib 預設、學界共識
換完跑 pnpm dev,使用者打開首頁,第一句話:「顏色不好看。」
我愣了一下,因為這在我認知裡是「最對」的選擇。viridis 的 perceptual uniformity 是真本事——要精讀數值、要在連續漸層上分辨細微差距,它確實比 OrRd 強。但回頭看截圖 — 紫色 → 黃色的漸層在一般民眾眼裡確實很疏遠,沒有「熱度地圖」的直覺。問題不是 viridis 不好,而是它的優化目標(精讀、跨媒介穩定)跟我這張地圖的目標(讓一般人一眼看懂熱度)不一致。那一秒我才真正聽進去。
找原型:kiang/salary 怎麼做?
我問使用者:「要不要參考一下其他人怎麼選的?」最快的途徑是看 kiang/salary(江明宗的村里所得地圖,TaxMap-TW 的精神祖父)的程式碼。
翻到 docs/map/main.js 找到一個 ColorBar(value) function:
function ColorBar(value) {
if (value == 0) return "rgba(255,255,255,0.6)" // 白
else if (value <= 300) return "rgba(254,232,200,0.6)"
else if (value <= 400) return "rgba(253,212,158,0.6)"
else if (value <= 500) return "rgba(253,187,132,0.6)"
else if (value <= 700) return "rgba(252,141,89,0.6)"
else if (value <= 900) return "rgba(239,101,72,0.6)"
else if (value <= 1100) return "rgba(215,48,31,0.6)"
else if (value <= 1300) return "rgba(179,0,0,0.6)"
else if (value <= 1500) return "rgba(127,0,0,0.6)"
else return "rgba(64,0,0,0.6)" // 最深
}短短 11 行,但裡面有兩個獨立決策被疊在一起:
- 用色:ColorBrewer OrRd 9 級(橙紅熱度)
- 分桶:絕對門檻(300/400/500/700/900/1100/1300/1500 千元,hard-coded)
我之前的選擇是:
- 用色:YlGnBu / viridis(隨意換)
- 分桶:quintile(程式自動算每年的 20/40/60/80 分位數)
Ah ha。我一直把兩個獨立決策當成一個決策。
拆開看兩個軸
把它們攤開:
| 軸 | 選項 | 影響 |
|---|---|---|
| 用色 | YlGnBu / viridis / OrRd / RdYlBu / Cividis… | 視覺氣質、色盲友善度、情緒聯想 |
| 分桶 | quintile / equal-interval / Jenks / 手動 / log 絕對 | 跨年穩定度、outlier 處理、視覺均勻度 |
quintile 看起來很合理(每年自動切 20%),但對「跨年看趨勢」是災難 — 因為門檻每年變,同樣的 100 萬,在 2012 是綠色、在 2022 可能是黃色。使用者拖年度滑桿時整張地圖會閃色,卻看不出真正的改變。
絕對門檻沒這個問題,但要面對「outlier 怎麼處理」:kiang 的 9 級在 >1500 千元(150 萬)就封頂,但松山中華里 2022 中位數 526 萬,跟 200 萬的里會被染成同一個深紅,看不出差別。
解法:OrRd 7 級 + 對數絕對門檻
把兩個決策獨立優化:
用色:OrRd 7 級
- 暖紅本來就是「熱度地圖」的視覺直覺
- 單色 sequential 不會像 RdYlBu 雙向被讀成「好 / 壞」
- kiang 已驗證好看
- 從 OrRd 9 級手挑 7 色子集(不是 ColorBrewer 官方 OrRd[7]),比 9 級少 2 級,視覺不擁擠
這裡要誠實補一句:OrRd 是單色順序色階,色盲友善度其實不如 viridis(viridis 整條對各類色覺缺陷都安全,這是它最硬的優點,前面拿這點打它其實是我選邊站後的雙標)。我把色盲友善降為次要考量,是因為這張地圖的受眾是一般民眾、且色階靠「明度由淺到深」也能讀出高低——而且 ColorBrewer 仍把 OrRd 標為 colorblind-safe,不是裸奔。如果受眾換成需要精準辨色的專業使用者,這個取捨我會重做。
分桶:對數絕對門檻
- 倍率 ~1.5×:30 / 50 / 80 / 130 / 200 / 350 萬(單位千元為 300 / 500 / 800 / 1300 / 2000 / 3500)
- 所得本來就 log-normal 分布,log 倍率切桶最自然
- 中產區段(50–130 萬)佔最寬視覺空間
- Outlier(>350 萬)自己一個頂色,中華里 526 萬獨立深紅,跟 200 萬區分得開
實作很短:
// src/components/MapClient.ts
// 注意:這不是 ColorBrewer 官方 OrRd[7](官方首色 #fef0d9、末色 #990000)。
// 我是從 OrRd 9 級手挑出 7 色子集,跳掉中間兩階讓對比更開。
const ORRD_7 = [
'#fee8c8', // <30 萬
'#fdd49e', // 30–50
'#fdbb84', // 50–80
'#fc8d59', // 80–130
'#ef6548', // 130–200
'#d7301f', // 200–350
'#7f0000', // >350
] as const;
const ORRD_BREAKS = [300, 500, 800, 1300, 2000, 3500]; // 千元paint expression 把每個 VILLCODE 對應到 stats、查 bucket 後上色:
private classifyValue(value: number): number {
for (let i = 0; i < ORRD_BREAKS.length; i++) {
if (value < ORRD_BREAKS[i]) return i;
}
return ORRD_BREAKS.length; // 6 = >350 萬最深紅
}整段比 quintile 版簡單 — 因為門檻是常數,不再需要每次切換指標都重算 Jenks。
具體數據 / 結果
跟 kiang 比的改進:
| kiang | TaxMap-TW | |
|---|---|---|
| 用色 | OrRd 9 級 | OrRd 7 級 |
| 分桶數 | 9 級 + 0 | 7 級 + 無資料灰 |
| 最高門檻 | >150 萬一個色 | >350 萬一個色 |
| 中產解析度 | 50–130 萬擠在 2 級 | 50–130 萬攤開到 3 級 |
| 中華里 526 萬 | 跟 200 萬同色 | 獨立深紅 |
| 跨年穩定 | ✓(絕對門檻) | ✓(絕對門檻) |
| 透明度 | 0.6 半透明 | 0.85 較飽和 |
跟原本自己 quintile 版的差距更大 — 之前拖滑桿整張地圖在閃色,現在拖滑桿只有「真正有變化的里」會升降顏色,視覺訊號終於跟資料變化對齊。
**這個方案的代價我也得說清楚:**一組固定門檻(30/50/80/130/200/350 萬)是照「綜所稅中位數」的量級調的,但我有 4 個指標可切(中位數、平均、各分位)。平均數那檔的數值分布跟中位數不一樣,套同一組門檻時,低收入村里會偏擠在前一兩桶,解析度沒有中位數那檔漂亮——嚴格講每個指標該有自己的一組門檻,我為了「跨指標也用同一把尺」偷懶用一組,這是已知的妥協。另外那個「>350 萬獨立深紅」聽起來解決了 kiang 的封頂問題,其實只是把 cap 從 150 萬往後推到 350 萬而已;中華里 526 萬跟假設某天冒出個 900 萬的里,還是會被染成同一個 #7f0000。outlier 永遠有,我只是把封頂線移到「現階段資料碰不到」的地方,不是真的解決了它。
反思
技術面
Choropleth 色階是兩個獨立決策,不要疊在一起想:
- 用色(hue / palette):解決「視覺氣質」與「色盲友善」
- 分桶(binning):解決「跨年穩定度」與「outlier 處理」
下次再看到任何 dataviz 設計問題卡住,先問自己:「這真的是一個決策嗎?還是兩個被綁在一起?」
log 倍率 binning 在「對的前提下」是被低估的選擇——但它有前提:
它對我這個場景好用,是因為剛好滿足三個條件:資料是 log-normal 分布、全正值、而且有公認的 anchor(所得級距、loan tier 那種大家認得的數字)。對應地:
- 適合 log-normal 且全正的資料:所得、檔案大小、網站流量、收入級距、地震規模
- 比 quintile 多了「絕對意義」(100 萬永遠是同色),所以能跨年比
- 比 equal-interval 不會被 outlier 拉爆
- 比手動 thresholds 容易解釋(「倍率 1.5x 切」一句話講完)
但只要前提不成立就別硬套:資料含 0 或負值(log 直接爆)、近常態分布(log 反而把中間擠扁)、你要看的是相對排名而非絕對值、或資料偏態到大量村里全擠進同一桶——這些情況絕對門檻都會輸。而 quintile 也不是只有缺點:它保證每個色階都分到差不多的樣本數,做「單年、單指標的分布快照」時,這個「每色都有料」的特性其實比絕對門檻好看也好讀。我換掉它純粹是因為 TaxMap 的核心是「跨年拉滑桿看趨勢」,不是因為 quintile 本身爛。
抄前人的程式碼遠比從零推快:
- kiang 11 行
ColorBar()包含了他幾年累積的設計判斷 - 我看一眼就拿到「絕對門檻」的關鍵 insight
- 但我沒照抄,看完後問「他這樣做的痛點在哪?我能不能改進?」 — 結果改成 7 級 + log 倍率 + 更高的 cap
心態面
「好看」是合法的產品需求。 我一開始把使用者「顏色不好看」當成主觀偏好,差點要去說服他 viridis 才是正確答案。回頭看那是傲慢 — 一張公開的地圖是給一般民眾看的,不是給 matplotlib 用戶。學術上對 ≠ 產品上對。前提是「好看」不能踩到底線:可及性(色盲能讀)跟正確性(顏色沒有誤導數值)是不能用美感換的,這次只是色盲友善降為次要、沒被犧牲掉。
「matplotlib 預設」不是中立選擇,是別人的優化目標。 viridis 是 2015 年 matplotlib 為「科學論文 print 出來在黑白紙上、影印後、色盲眼裡都讀得到」設計的——這目標很值得尊敬,只是它跟 web choropleth 的痛點不重疊。所以不是「viridis 不該用」,是「它的優化目標不該無條件套到我的場景」。盲目套用業界標準,等於把別人的優化目標當成自己的。
少嘴砲、先打開別人的程式碼。 我花了一小時跟使用者來回討論色階理論,最後實際解決問題的關鍵 insight,是花 30 秒讀 kiang 11 行 javascript 拿到的。但讀前人 code 要帶批判——它包的是「他的痛點」的答案,不一定是你的,所以我看完是問「他為什麼這樣切?我的場景哪裡不一樣?」,而不是整段抄走。
有趣發現
ColorBrewer 名字超難記但網站超實用。 colorbrewer2.org 是 Cynthia Brewer 教授 2002 年做的 choropleth 配色工具,內建 35+ 個色階分 3 類(sequential / diverging / qualitative)。每個都有色盲模擬、列印友善、影印友善的標記。地圖配色 99% 用得到,但因為網站做得很學術老派,常被忽略。
換成暖紅之後,沒人再問「這顏色代表什麼」。 viridis 版我得跟使用者解釋「紫是低、黃是高」;OrRd 版打開來,他直接就說「喔右邊那塊比較紅就是有錢的」。紅=熱=高這個聯想在我這個使用者身上是零成本的——我不敢說它跨文化都成立,但對這張給台灣民眾看的地圖夠用了。
對數倍率 1.5× 不是亂猜的,是公部門統計手冊的「level set」傳統。 Loan / income tiers 常切 30/50/80/130/200/300/500 萬 — 看起來只是「順手挑的數字」,其實是平均所得倍率累積的結果。我 TaxMap-TW 用 30/50/80/130/200/350,差不多一脈相承。
寫在最後
如果這兩週只留一句給未來的自己,那會是:色階卡住的時候,我反覆換的多半是「色卡」,但真正卡住我的是「分桶」。先把這兩件事拆開,再決定「我這張圖到底要跨年比、還是看單年分布」,色階就不再是玄學了。至於要不要抄前人的 OrRd——抄判斷,不抄結論。
參考連結
- TaxMap-TW GitHub
- kiang/salary 原型
- ColorBrewer 2.0
- 這篇承接的決策起點:資料地圖該用哪種色階?viridis、YlGnBu 與 ColorBrewer 實戰指南(當初選 YlGnBu 的理由,這篇把它推翻了)
- 同樣是「視覺優先 vs 教科書正解」的權衡:地圖標籤密集時,competition ranking 還是 dense ranking?
- 系列總結:打造 TaxMap-TW 完整心得:6 個技術決策、踩了 4 個坑