Multi-Agent 編排實戰:我怎麼讓 Claude Code、OpenClaw、n8n 三個 Agent 協作

這是「Agentic Engineering 實戰手冊」系列的第十篇。上一篇:MCP 與 A2A 協議實戰
理論上我有一支 AI 軍隊,實際上它們像三個不太會溝通的實習生
我的日常有三個 AI agent 在跑:Claude Code 負責寫 code、OpenClaw 負責每日 briefing 和調研、n8n 負責自動化 workflow。理論上,這是一支全天候的 AI 團隊。
實際上?Claude Code 不知道 OpenClaw 今天早上幫我整理了什麼重點。OpenClaw 不知道昨天 coding session 做到哪了。n8n 觸發的 automation 偶爾會跟 Claude Code 正在做的事情衝突。
三個很強的 agent,各自為政。
Multi-agent orchestration 不是「有很多 agent」。是「讓很多 agent 像一個團隊一樣工作」。這兩件事之間的差距,比你想的大得多。
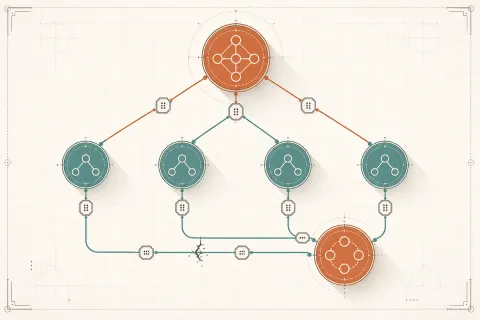
我的三 Agent 架構
Agent 1:Claude Code — 核心開發者
職責:寫 code、修 bug、review PR、重構、寫測試 運行環境:本地 terminal + IDE integration 記憶方式:CLAUDE.md + memory system + conversation history 工作時間:我開電腦的時候(~8-10 小時/天)
Claude Code 是主力。我 80% 的生產力來自它。它有完整的 codebase access、MCP 工具、和一年累積的 CLAUDE.md 設定。
Agent 2:OpenClaw — 研究分析師
職責:每日 briefing(技術新聞、產業動態)、深度研究(競品分析、技術選型)、內容策劃 運行環境:雲端,每天 6:00 AM 自動執行 記憶方式:Notion database + 結構化輸出 工作時間:每天自動跑一次 + 我手動觸發研究任務
OpenClaw 是我的「情報官」。它每天早上自動整理我追蹤的領域的最新動態,讓我不需要花時間刷 Twitter 和 Hacker News。
Agent 3:n8n — 自動化管家
職責:workflow automation——GitHub webhook 處理、Notion 同步、定時任務、跨系統串接 運行環境:self-hosted n8n instance 記憶方式:workflow 狀態 + execution logs 工作時間:24/7 always-on
n8n 不做「思考」的工作。它做的是「當 X 發生時,執行 Y」的 deterministic automation。GitHub 有新 PR → 自動通知 Slack。Blog post 更新 → 自動觸發 build。
為什麼是這三個
這個組合不是隨便選的。核心設計原則是 non-overlapping responsibilities:
┌─────────────────┐
│ Human (我) │
│ 決策、Review、方向 │
└────┬───┬───┬────┘
│ │ │
┌─────────────┤ │ ├─────────────┐
│ │ │ │ │
┌────▼────┐ ┌─────▼───▼──┐ ┌──────────▼┐
│ OpenClaw │ │ Claude Code │ │ n8n │
│ Research │ │ Coding │ │ Automation │
│ Morning │ │ On-demand │ │ 24/7 │
└──────────┘ └─────────────┘ └────────────┘每個 agent 有明確的「地盤」。沒有兩個 agent 負責同一件事。當兩個 agent 的職責重疊時,問題就來了。
職責重疊的慘案
有一次我同時讓 Claude Code 寫一個新的 API endpoint,又讓 n8n 的自動化在同一個 repo 上跑 auto-format。結果 n8n 的 formatter 在 Claude Code 還在寫的時候就 commit 了一個格式修正,造成 Claude Code 的 working directory 突然有了 unexpected changes。
Agent 非常不擅長處理「有人在我背後改了東西」的情況。它不知道那些 changes 是 n8n 做的 auto-format,以為是自己剛才寫的 code 的一部分,然後在上面繼續 build——結果是一團混亂。
教訓:一個任務只能有一個 owner。如果 Claude Code 在寫 code,n8n 的 auto-format workflow 就暫停。
Context 如何在 Agent 之間傳遞
這是 multi-agent 最難的部分。不是技術上難(你可以用 file、API、database),是設計上難——什麼資訊需要傳遞?傳遞多少?什麼時候傳遞?
Markdown as Shared Memory
我目前的做法是用 Markdown 文件作為 agent 之間的共享記憶:
~/.claude/projects/{project}/memory/
├── MEMORY.md ← index:所有 memory 的目錄
├── user_role.md ← 關於我的資訊
├── project_status.md ← 專案進度
├── decisions.md ← 重要決策紀錄
└── lessons.md ← 學到的教訓為什麼用 Markdown 而不是 Database?
- Human-readable:我可以直接打開看,不需要 query tool
- Git-trackable:可以 version control,看到記憶的變化歷史
- Agent-native:所有 LLM agent 都擅長讀寫 Markdown
- Zero infrastructure:不需要額外的 database 或 API server
Hot / Warm / Cold 三層記憶
不是所有資訊都需要即時同步。我把 memory 分三層:
| 層級 | 內容 | 同步頻率 | 存放位置 |
|---|---|---|---|
| Hot | 當前 task 的 context、進行中的決策 | 即時 | Conversation / Plan file |
| Warm | 專案狀態、近期決策、常用 patterns | 每 session | Memory files |
| Cold | 歷史決策、舊的 lessons learned | 不主動同步 | Memory archive |
Claude Code 開始新 session 時,自動載入 Warm 層的記憶(透過 MEMORY.md index)。Hot 層在 session 內即時產生。Cold 層只在明確需要時才去讀。
Agent 之間的接力棒
一天的流程看起來像這樣:
06:00 OpenClaw → 產出 daily briefing → 寫入 Notion
09:00 我 → 讀 briefing → 決定今天做什麼
09:05 Claude Code → 載入 memory + 今天的 task list → 開始工作
...(Claude Code 工作整天)...
18:00 Claude Code → session 結束 → 更新 memory/project_status.md
18:00 n8n → 偵測到 session 結束 → 觸發 daily summary workflow
21:00 我 → review daily summary → 調整明天的優先級關鍵在 handoff 的時刻——每個 agent 結束工作時,要把「我做了什麼、目前狀態是什麼、下一步建議是什麼」寫到共享記憶裡,讓下一個 agent(或明天的自己)可以無縫接手。
為什麼我沒用 LangGraph / CrewAI
我試過的框架:
LangGraph
優點:最靈活。你可以定義任意複雜的 agent 互動圖。支援條件分支、循環、人工介入點。 缺點:學習曲線陡。為了設定一個兩 agent 的 pipeline,我寫了 200 行 boilerplate code。而且 debug 困難——graph 一複雜,你很難追蹤「資料是從哪條路徑流過來的」。
結論:如果你需要 10+ agents 的複雜編排,LangGraph 是對的選擇。如果你只有 2-3 個 agent,overhead 大於效益。
CrewAI
優點:角色定義直觀(“you are a researcher”, “you are a coder”)。設定快。 缺點:太 opinionated。它預設了一套 agent 互動模式,如果你的 workflow 不符合那個模式,客製化很痛苦。而且它跟特定的 LLM provider 綁得比較深。
結論:快速 prototype 很好用,但 production 使用的靈活度不夠。
Google ADK(Agent Development Kit)
優點:跟 Google 生態系(Gemini、Vertex AI)整合好。 缺點:Gemini 優化,用在其他 model 上效果打折。生態系還在早期。
Microsoft Agent Framework
優點:企業級。跟 Azure、Microsoft 365 整合。 缺點:Azure-heavy。如果你不在 Azure 生態系裡,很多功能用不上。
我的結論:手動編排就好
對於大部分個人開發者和小團隊來說,手動編排比框架更適合:
| 手動編排 | 框架 | |
|---|---|---|
| 透明度 | 完全看得見 | 黑盒子(尤其 debug 時) |
| 靈活度 | 想改就改 | 被框架 API 限制 |
| 學習成本 | 接近零 | 需要學框架 |
| 維護成本 | 低 | 跟框架版本走 |
| 適合場景 | 2-5 agents | 5+ agents |
手動編排的意思是:我自己決定哪個 agent 做什麼、怎麼傳遞 context、怎麼處理衝突。不用框架,用 files + webhooks + 少量 script。
什麼時候該用框架?
- 你有 5 個以上的 agent 需要複雜互動
- 你需要 deterministic orchestration(金融、醫療等合規要求)
- 你的團隊有多人需要共同維護 agent pipeline
- 你需要 observability 和 audit trail
如果以上都不符合,從手動開始。需要框架的時候你會知道的。
Error Handling:當 Agent 們意見不一致
衝突類型 1:搶資源
兩個 agent 同時修改同一個檔案 → git conflict。
解法:嚴格的 ownership 規則。一個時間點,一個檔案只能被一個 agent 操作。如果 n8n 需要改 config file,Claude Code 那段時間就不能碰那個 file。
衝突類型 2:不同建議
OpenClaw 的 research 說「應該用 Library A」,Claude Code 在實作時發現 Library A 有 bug,改用了 Library B。隔天 OpenClaw 又建議 Library A。
解法:決策一旦做出就記錄到 shared memory(decisions.md),所有 agent 都要先讀決策紀錄再給建議。
衝突類型 3:Automation 時機不對
n8n 在 Claude Code 正在做 interactive rebase 的時候觸發了 auto-lint → 搞亂了 git 狀態。
解法:n8n 的 automation 都加了「check if coding session active」的前置條件。如果有 coding session 在跑,non-critical automation 排隊等候。
核心原則:Human as Final Arbiter
當 agent 之間有衝突,最終裁決者永遠是人。不要設計一個 agent 來「管理」其他 agent 的衝突——那個 meta-agent 本身也可能犯錯,而且增加了系統複雜度。
在現階段,最可靠的 conflict resolution 是:agent 發現衝突 → 暫停 → 通知人類 → 人類決策 → agent 繼續。
給想開始的人的建議
Phase 1:先把一個 Agent 用到極致
不要一開始就想搞 multi-agent。先把 Claude Code(或你的主力 coding agent)的潛力完全發揮——好的 CLAUDE.md、完善的 spec workflow、可靠的 QA 流程。
Phase 2:加第二個 Agent 做非 coding 的事
當你覺得「coding agent 很好了,但我花太多時間在 research / admin / automation 上」的時候,加第二個 agent。確保它的職責跟第一個完全不重疊。
Phase 3:用 Automation 串接
n8n(或 Zapier / Make)作為黏合劑,把兩個 agent 的 output 串接起來。不需要它們直接對話,只需要它們共享結果。
Phase 4:需要的時候再加框架
99% 的人在 Phase 2-3 就夠了。如果你發現自己需要更複雜的編排——恭喜,你可能是那 1%,可以開始看 LangGraph。
Takeaway
-
Multi-agent 的價值在「分工」而非「數量」——三個各有專精、職責不重疊的 agent,比十個通才 agent 強。設計 agent team 的第一步不是選工具,是定義「誰負責什麼,以及誰不負責什麼」。
-
Context sharing 是最難的部分——Markdown as shared memory 是目前最實用的方案。簡單、human-readable、git-trackable、零基礎設施成本。Hot / Warm / Cold 三層分離,避免每次都載入全部。
-
從手動編排開始,需要框架時再加——LangGraph / CrewAI 這些框架適合 5+ agents 的複雜場景。大部分人只需要 2-3 個 agent + files + webhooks 就夠了。先把一個 agent 用到極致,再想 multi-agent。
上一篇:MCP 與 A2A 協議實戰 下一篇:Token 經濟學進階