延遲、可靠性、成本:AI agent 系統設計的鐵三角

本篇是「從 PoC 到 Production:企業 AI Agent 系統工程」系列的第 10 / 12 篇。你可以從系列總覽開始閱讀,也可以直接接著看本文。
這是「從 PoC 到 Production:企業 AI Agent 系統工程」系列第 10 篇(共 12 篇)。上一篇:生產級 LLM 可觀測性與評估。
到這篇,前面講的所有東西要付帳了。RAG 多檢索幾份文件、reranking 多一次模型呼叫、multi-agent 多幾顆 agent、retry 多跑幾次——每一個讓系統「更好」的決定,都在延遲、可靠性、成本這三件事上劃下一刀。
而這三件事,是一個互相打架的鐵三角:
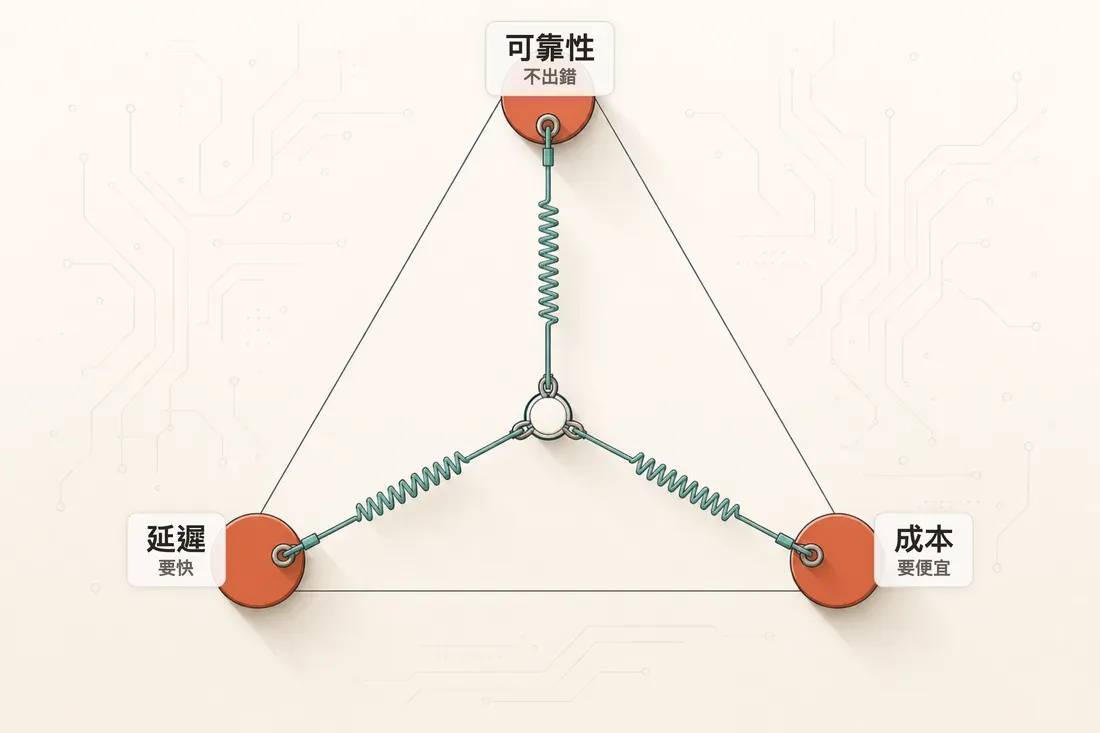
可靠性、延遲、成本互相拉扯的鐵三角:靠近任一角,另外兩角就被犧牲——三者無法同時拉到極致。
- 想可靠 → 加 retry、加 fallback、用更強的模型 → 變慢、變貴。
- 想便宜 → 用小模型、少檢索、少 reasoning → 品質和可靠性下降。
- 想快 → 砍 reasoning、激進 cache、少檢索 → 可能犧牲正確性。
你不可能三個都要到極致。Production 工程的價值,就是在這個三角上做出有意識的取捨,而不是預設「全都要最好」然後被帳單和延遲教訓。
這也是我一直強調 LLM app 還是 distributed system 的原因——下面這些手段,做過後端的人會覺得無比熟悉。
延遲:先區分「真延遲」和「感知延遲」
LLM 天生慢,一個複雜回答跑好幾秒是常態。但使用者體感的「慢」,跟實際耗時是兩回事。
1. Streaming(串流)幾乎免費降感知延遲。 別等整個答案生成完才一次吐出來,邊生成邊吐字。實際總耗時沒變,但使用者「立刻看到東西在動」,體感快非常多。這是 CP 值最高的一招,幾乎沒有不做的理由。用工程語言講,streaming 壓的是 TTFT(Time To First Token,首 token 延遲)——聊天場景只要 TTFT 低於 1 秒,使用者就覺得「即時」;串流開始後順不順,則看 TBT(token 之間的間隔)。人對「按下送出到看到第一個字」的等待,遠比「字與字之間的間隔」敏感,所以該進你第 9 篇 dashboard、該設 SLO 的,是 TTFT,不是籠統的「總回應時間」。
2. 把能平行的就別串行。 如果一個任務要檢索三個不同來源,讓它們同時跑,而不是一個等一個。Agent runtime(第 2 篇)要支援這種平行。這是基本的並行思維,跟你優化任何後端流程一樣。
3. 用小模型處理快路徑。 不是每一步都要動用最強最慢的模型(下面 model routing 細談)。意圖分類、簡單抽取用快的小模型,把慢的大模型留給真正需要的那一步。
可靠性:為「外部依賴一定會出包」設計
你的 agent 依賴外部 LLM API,而那是一個會逾時、會限流、會偶爾回垃圾、偶爾掛掉的依賴。把它當成「一定會出包的外部服務」來設計,這又是後端的老功課:
- Timeout:每次模型呼叫設合理逾時,別讓使用者無限等。
- Retry with backoff:暫時性錯誤(限流、逾時)重試,但要退避、要設上限,別把對方打更慘、也別自己燒爆 token。
- Circuit breaker:某個模型 / 供應商持續出錯,先「跳閘」停止打它,走 fallback,給它時間恢復。
- Fallback model:主模型掛了或回垃圾,自動切備援(另一家供應商、或本地模型)。這也降低單一供應商的依賴風險。
- 降級(graceful degradation):真的都不行時,老實回「現在無法處理,請稍後或轉人工」,而不是給一個爛答案。呼應第 1 篇的鴻溝六。
注意這裡的張力:每加一層可靠性(retry、fallback),通常就多一點延遲、多一點成本。所以要分場景——關鍵動作值得多付,邊緣功能不必。
關於 fallback 還有個坑要先講:跨供應商 fallback 沒有「一鍵切換、行為一致」那麼無痛。同一段 prompt 在 GPT、Claude、Gemini 上的輸出風格、JSON 遵循度、refusal 行為都不一樣;tool calling 的 schema 各家也不同;更別說等下要講的 prompt caching 是供應商綁定的——切到備援那一刻,前面省的快取全部失效,延遲跟成本反而往上跳。實務上只有兩條路:為主 / 備各自維護一套 prompt 與 parser,或把備援路徑當成「可接受的降級」來設計。別假設換家供應商,行為會一樣。
成本:LLM 系統獨有的「浮動帳單」
傳統服務成本相對固定(機器開著就那樣)。LLM 系統的成本是按 token 浮動的,而且會悄悄長大。第 9 篇我們已經把成本監控起來了,這篇講怎麼壓。
1. Model routing:小模型優先,必要才升級。 這是最大的省錢槓桿。把「要用哪個模型」抽成一層(第 2 篇的 Model Router),依任務難度路由:
- 分類、抽取、格式轉換、簡單問答 → 便宜小模型
- 複雜推理、需要高品質的最終生成 → 大模型
光是把「不需要大模型的步驟」改用小模型,常常就能砍掉一大塊成本,而品質幾乎無感。
有多大?拿 RouteLLM(UC Berkeley / Anyscale / Canva,ICLR 2025)的公開 benchmark 當參考:在偏對話的 MT-Bench 上,它能維持約 95% GPT-4 品質、成本卻砍掉約 85%。但別把這 85% 當保證值——同一個 router 換到偏推理的 benchmark,省幅就掉很多(MMLU 只省約 45%)。所以 routing 的省幅,本質上等於你流量裡「不需要大模型的那一塊」有多大:先量你自己的流量分布,再決定能省多少,別套別人的數字。
2. Cache:能不重算就不重算。
- 結果快取:這裡其實藏了兩種完全不同難度的東西。Exact cache(把 query 正規化後當 key,同樣的問題回同樣的答案)幾乎零風險、該最先做;semantic cache(用 embedding 相似度命中「相似」問題)能多抓改寫過的重複,但有 false-positive 風險——兩個在向量空間很近的問題可能需要完全不同的答案,而且對的命中跟錯的命中相似度高度重疊,沒有通用安全閾值,閾值要訂多嚴取決於「答錯的代價」。生產數據也顯示 semantic cache 相對 exact 往往只多 5~8 個百分點命中率,未必抵得過它的複雜度與答錯風險。高風險場景就乖乖用 exact。(兩種都要注意時效和權限,別把 A 使用者的答案快取給 B。)
- Embedding 快取:同一段文字別重複 embedding。
- Prompt 快取:把穩定的內容(system prompt、few-shot 範例、長 context)放最前面、把每次都變的部分放最後,讓固定前綴可以被快取重用。但 2026 三家機制不一樣,這差異直接決定你有沒有真的省到:OpenAI、Gemini 是自動命中(前綴 ≥ 1,024 token 重複就生效,讀取省 50~90%、寫入不收費);Anthropic 是顯式 opt-in,你得在 request 裡標
cache_control斷點,cache read 只要基礎 input 價的約 0.1 倍(省 ~90%),但 cache write 要付約 1.25 倍溢價、預設 5 分鐘 TTL——換句話說 Claude 的快取要至少命中一次才回本。用 Claude 卻忘了標cache_control=你以為在省錢、其實一毛沒省,這是這招最常見的踩雷。
3. 管好 context 長度。 Token 成本跟 context 長度直接相關。第 7 篇講的記憶截斷 / 摘要、第 3 篇講的別塞太多 chunk,到這裡全都變成「省錢」的具體手段。把不必要的東西塞進 context,是最常見的浪費。
4. 設預算護欄。 單一請求、單一使用者、單一 multi-agent 任務(第 8 篇的成本爆炸風險)都要有 token / 花費上限。撞到上限就停下來或降級,別讓一個失控迴圈燒出一張嚇人的帳單。
我做過 K8s 叢集那類的雲端成本優化,心法在這裡完全通用:先讓成本可見(第 9 篇),找出最大的那塊,用最小的品質代價把它砍掉。差別只是這次砍的不是 CPU/記憶體,是 token。
把三角畫出來:依場景做取捨
最後給一個務實的框架。不同功能在三角上的位置不該一樣:
| 場景 | 優先 | 取捨 |
|---|---|---|
| 即時對話助理 | 延遲 | streaming、小模型快路徑、適度 cache,容忍偶爾要重問 |
| 高風險決策 / 報告 | 可靠 + 正確 | 大模型、多檢索、critic 審查、HITL,接受慢和貴 |
| 大量批次處理 | 成本 | 小模型、激進 cache、可離線慢慢跑,犧牲即時性 |
| 內部低頻工具 | 成本 + 簡單 | 別過度工程,能跑就好 |
關鍵不是背這張表,是養成一個習慣:每設計一個 agent 功能,先問它在這三角的哪個角,然後刻意往那邊取捨——而不是無意識地全都要最好,最後三個都普普、帳單還很貴。
小結
- 延遲、可靠性、成本是會互相打架的鐵三角,不可能三個都極致。
- 延遲:streaming 降感知延遲、平行化、小模型走快路徑。
- 可靠性:把 LLM API 當「一定會出包的外部依賴」——timeout、retry、circuit breaker、fallback、降級。
- 成本:model routing 是最大槓桿,加上 cache、管好 context、設預算護欄。
- 每個功能依它在三角的位置刻意取捨,這份判斷力就是 production 系統工程師的核心價值。
這些手段你會發現沒一個是 AI 玄學,全是分散式系統的硬功夫換了對象。下一篇,我們把第 5、6、9 篇散落的安全與信任機制,收斂成一套完整的Agent 治理框架——讓企業敢把這套系統接到真實業務上。
文章簡報








延伸閱讀
- 上一篇:生產級 LLM 可觀測性與評估
- Agentic Engineering:成本優化——agent 工作流的 token 成本怎麼省
- 下一篇:《Agent 治理框架:RBAC、audit log、HITL、tool registry》