多代理協作:什麼時候真的需要 multi-agent,什麼時候那只是讓系統更貴
本篇是「從 PoC 到 Production:企業 AI Agent 系統工程」系列的第 8 / 12 篇。你可以從系列總覽開始閱讀,也可以直接接著看本文。
這是「從 PoC 到 Production:企業 AI Agent 系統工程」系列第 8 篇(共 12 篇)。上一篇:Agent memory 與狀態管理。
「多代理」(multi-agent)是這兩年最性感的詞之一。一堆 agent 各司其職、互相協作、像個團隊——聽起來就很厲害。但我要先潑一盆冷水,因為這是我看過最多人為了用而用、結果把系統搞得又貴又難 debug 的地方。
所以這篇反過來寫:先講什麼時候不要用,再講真的要用時怎麼用。
先記住這句話:預設用單一 agent
大多數你以為需要 multi-agent 的場景,其實一個 agent 加上一組好工具(第 6 篇)就解決了,而且更便宜、更好 debug。
為什麼?因為每多一個 agent,你就多了:
- 一次(或多次)額外的模型呼叫 → 更貴、更慢(第 10 篇)。
- 一個 context 傳遞的接縫 → agent A 的理解要傳給 agent B,這中間一定會流失資訊、產生誤解。
- 一個更難追的失敗點 → 出錯時,是哪個 agent 錯的?是它本身錯,還是它接收到的 context 已經被前一個 agent 弄歪了?
- 錯誤會傳染 → A 給了 B 一個錯誤前提,B 在錯誤前提上認真工作,整條鏈一起歪。
別小看這幾條的代價。Anthropic 自己揭露過一組值得背起來的數字:agent 大約用掉 chat 的 4 倍 token,multi-agent 系統更高達約 15 倍。換句話說,你還沒讓系統變聰明,光是把它拆成多個 agent,帳單就先乘了 15 倍上去。
這些成本是實打實的。所以決定用 multi-agent 之前,先誠實問自己:單一 agent 配好工具,真的解不了嗎? 很多時候答案是「能,我只是覺得多 agent 比較酷」。
什麼時候 multi-agent 真的有價值
有三種情況,多代理確實划算:
1. 任務天然可以平行拆分。 比如「分析這 20 份競品報告」,拆成 20 個 agent 各讀一份、最後彙整,比一個 agent 慢慢讀快很多。這裡的價值是平行,不是「聰明」。
2. 需要的能力 / 權限差異很大。 一個負責「讀取分析」、另一個負責「執行高權限寫入動作」。把它們分開,是為了權限隔離(第 5、6 篇)——讓會動手的那個 agent 只有最小必要權限,唯讀分析的那個碰不到危險工具。這是安全考量驅動的拆分,很合理。
3. 需要對抗 / 審查的結構。 一個 agent 產出、另一個 agent 專門挑錯(critic)。這種「生成 vs 審查」的張力,確實能提升品質——本質上是把「自我檢查」外部化成一個獨立角色。
注意這三個的共通點:拆分有明確的工程理由(平行、隔離、對抗),不是為了模擬一個公司組織圖。
這個判斷不是我一個人的偏執。2025 年 6 月有一場被社群並列為「同一週對打」的公開辯論:Anthropic 發表《How we built our multi-agent research system》,主張在可平行的廣度研究任務上拆 agent 很划算——他們的多 agent 系統在這類任務上比單一 agent 高出 90.2%;幾乎同一週,做 Devin 的 Cognition(Walden Yan)發表《Don’t Build Multi-Agents》,主張預設就用單執行緒的線性 agent、別輕易拆。
表面上兩篇在打架,細看卻不矛盾——差別只在「這個任務是不是真的能平行解耦」。有趣的是 Anthropic 自己也點名:大多數 coding 任務「真正可平行的部分比研究少很多」,因為各部分彼此相依、要共享同一份 context,硬拆反而會撞車。所以判斷能不能平行,看的不是表面能不能分工,是分出去的子任務彼此依賴有多深——讀競品報告可以各讀各的,寫一個 feature 通常不行。
幾種協作模式
真的要做了,常見的結構有這幾種:
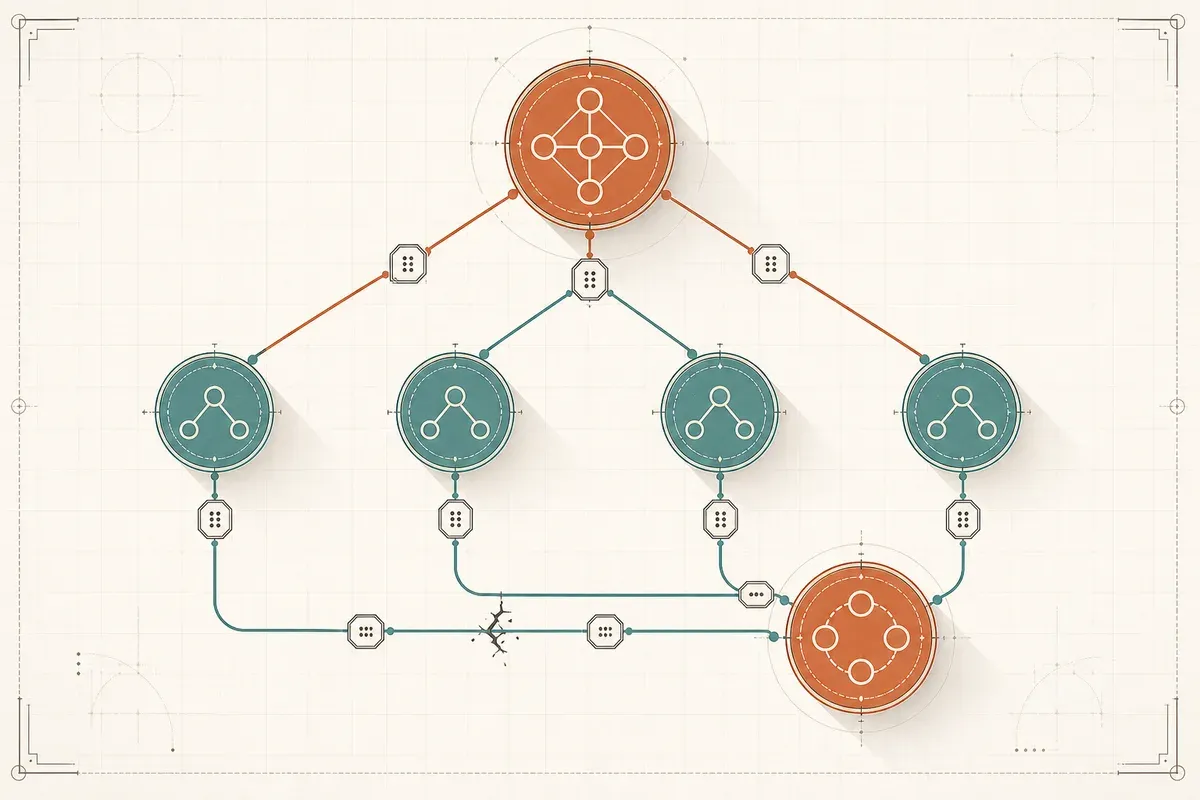
Supervisor / Worker(主管—工人)
一個 supervisor agent 負責拆任務、分派、彙整;底下幾個 worker agent 各做一塊。最常見、最好管,因為控制流集中在 supervisor,責任清楚。大部分企業場景用這個就夠。
Pipeline(流水線)
agent 串成一條線,A 的輸出是 B 的輸入(研究 → 草稿 → 審稿 → 定稿)。適合階段分明、單向流動的任務。要小心的是錯誤會沿著管線累積放大——第一棒歪一點,最後一棒可能歪很多。
Debate / Critic(辯論—審查)
多個 agent 對同一問題提不同觀點,或一個產出、一個反駁,最後收斂。品質好但最貴(同一問題算好幾遍),留給高價值、容錯低的決策用。
Handoff:接縫是最容易漏水的地方
多代理最脆弱的地方,是 agent 之間**交棒(handoff)**那一刻。A 要把它的理解傳給 B,這裡有兩個常見坑:
- 傳太多:把 A 的整段思考、所有中間產物全倒給 B,B 的 context 被灌爆、抓不到重點、又貴。
- 傳太少:只給 B 一個結論,B 缺了關鍵脈絡,只好自己腦補,腦補就錯。
好的 handoff 是設計過的介面:明確定義「A 交給 B 的,是哪幾個欄位、什麼格式」,像在設計兩個 service 之間的 API contract 一樣。這又回到系統工程——agent 之間的協作,本質是介面設計問題,跟微服務之間怎麼定 contract 是同一種思考。
這套「把 handoff 當 API contract」的想法,框架也已經幫你制度化了。OpenAI 的 Agents SDK 就把 handoff 做成一級原語:agent A 用一個類似 transfer_to_agent_b 的工具呼叫,把控制權加上一份結構化 payload 交給 B,整個轉移還會被記錄、可以重播;後續更新甚至把巢狀 handoff 的完整歷史改成預設 opt-in,正是為了減少跨 agent 的 context bleed——框架的演進方向,剛好就是這篇講的那套介面紀律。
錯誤隔離:別讓一個 agent 拖垮全部
Cognition 講過一個很有畫面感的翻車案例:他們把「做一個 Flappy Bird clone」拆成平行子任務,結果一個 subagent 把背景做成了 Super Mario 的風格,另一個 subagent 做的鳥又跟整體美術不搭。每個 subagent 單獨看都很合理,合起來卻是個四不像——因為它們看不到彼此在做什麼。這就是「接縫漏水」最具體的長相:不是哪個 agent 出 bug,而是它們各自正確、彼此不一致。
既然錯誤會傳染,就要主動隔離:
- 驗證交棒內容:B 接到 A 的東西,先做基本檢查(格式對不對、有沒有明顯矛盾),別照單全收。
- 限制爆炸半徑:一個 worker 失敗,supervisor 要能處理(重試、換人、降級),而不是整個任務崩掉。
- 設總預算上限:整個多代理任務要有 token / 時間 / 步數的天花板,否則一群 agent 互相觸發,可以把成本燒到失控(第 10 篇會細談這個「成本爆炸」風險)。
一個務實的決策流程
下次有人說「我們來做 multi-agent 吧」,照這個順序問:
- 單一 agent 配好工具能不能解? 能 → 就用單一,收工。
- 不能的話,是因為平行、權限隔離、還是需要對抗審查? 三個都不是 → 你大概其實不需要 multi-agent。
- 是的話,選最簡單能滿足的結構(通常是 supervisor/worker),把 handoff 當 API contract 設計,設好預算上限和錯誤隔離。
小結
Multi-agent 不是更高級的 agent,是一個有明確成本、要有明確理由才值得付的架構選擇。預設用單一 agent;只在平行、權限隔離、對抗審查這三種情況下拆分;拆分時把 agent 間的 handoff 當成介面設計,並嚴防錯誤傳染和成本爆炸。
這不只是我的經驗法則。做過最大規模多 agent 系統的 Anthropic,給的判準幾乎一模一樣:multi-agent 只在「任務價值高到足以支付那多燒的 token」時才划算。換句話說——能不能用,先算這題值不值得你多燒那 15 倍。
能忍住「不為酷而拆」,是這個主題上最值錢的判斷力——也是面試時很容易聽得出來「這個人到底有沒有真的做過」的地方。
前面八篇我們把系統的「能力面」蓋得差不多了:知道事情(RAG)、記得事情(memory)、做事情(tools)、協作(multi-agent)。接下來三篇轉向「能不能信任」這件事。下一篇先處理最基礎的:你怎麼知道這整套東西到底有沒有在好好運作——生產級的可觀測性與評估。
文章簡報










延伸閱讀
- 上一篇:Agent memory 與狀態管理
- 多代理協作的真實世界案例
- 用 Claude API 打造多代理系統
- 下一篇:《生產級 LLM 可觀測性與評估》