RAG 架構實戰:從文件 ingestion 到 source-cited 回答的每一步
本篇是「從 PoC 到 Production:企業 AI Agent 系統工程」系列的第 3 / 12 篇。你可以從系列總覽開始閱讀,也可以直接接著看本文。
這是「從 PoC 到 Production:企業 AI Agent 系統工程」系列第 3 篇(共 12 篇)。上一篇:企業 AI Agent 系統架構藍圖。
「我們做了 RAG」這句話,在 2026 年大概是企業 AI 專案裡最被濫用的一句。因為大部分人說的 RAG,是「把 PDF 切一切丟進向量庫,問問題的時候撈幾段塞給模型」。這個版本在 demo 會動,在 production 會用各種你想不到的方式翻車。
這篇把 RAG 拆成一條真正的 pipeline,一步一步講清楚每一步在幹嘛、設計取捨在哪、以及最容易踩的雷。
RAG 到底在解什麼問題
先講為什麼需要它。LLM 的知識凍結在訓練那一刻,而且它不知道你公司的事。你有兩條路讓它「知道」:
- Fine-tuning:把東西訓練進模型權重。但它真正擅長的不是塞知識,是塑行為——輸出格式、語氣、特定領域的推理模式、你公司的術語。拿它來灌會變動的事實知識才是用錯地方:知識一改就要重訓,而且權重裡的知識沒辦法做權限控制。
- RAG(檢索增強生成):知識留在外面,問問題時即時檢索相關片段,當作 context 餵給模型。
企業幾乎都拿 RAG 當起手式,原因不只是便宜——是因為RAG 的知識可以即時更新、可以做權限、而且答案可以附來源。最後這點,是企業敢不敢用的關鍵,後面會細講。
但別把這兩條路框成二選一。2026 最強的企業系統其實是 hybrid:fine-tune 管行為(格式、語氣、術語),RAG 管即時知識與來源 grounding,各司其職。而 fine-tuning 唯一在成本上真的贏過 RAG 的場景,是 query 量大到誇張、單次推理成本攤平了上線投資——對絕大多數企業,這個臨界點還很遠。
整條 pipeline 長這樣:
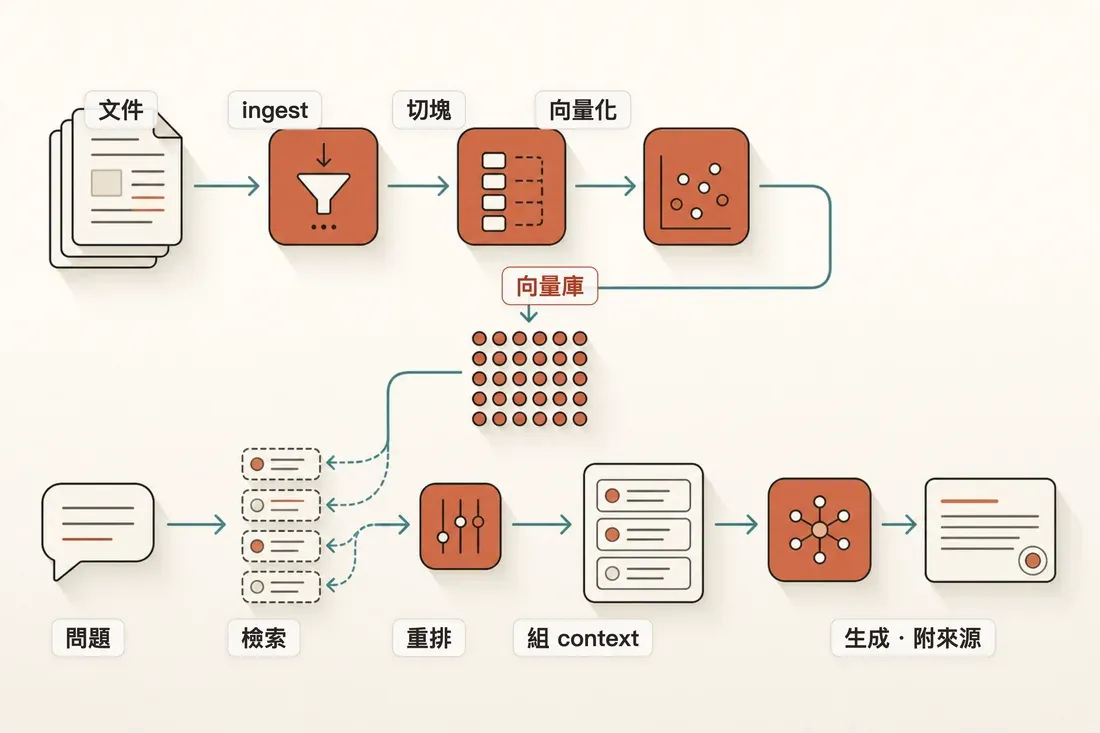
RAG 的兩段式流程:文件側做 ingest → chunk → embedding 入庫,查詢側做檢索 → rerank → 組 context → 生成並附上來源。
第一步:Ingestion,沒你想得單純
Ingestion 就是把各種來源(PDF、Word、Confluence、Notion、資料庫、工單系統)抽成乾淨的文字。聽起來無聊,但RAG 的品質上限,常常就卡在這一步。
幾個真實會痛的點:
- PDF 是地獄:表格被拆爛、兩欄式排版讀成一團、掃描檔根本是圖片。但解法在 2026 已經換代了——別再停在「先 OCR 抽純文字、再寫一堆後處理清資料」的舊心智模型。傳統的 OCR-only 工具(像 PyMuPDF)正是把表格拆爛的元兇;現在主流是用 VLM(vision-language model)做版面理解:看得懂閱讀順序、保得住表格結構、分得出標題段落圖表,直接吐出乾淨的 Markdown / JSON 餵給下游。想自管基礎設施可以看 Docling(開源),想快速起步可用 LlamaParse,其他像 Unstructured、Mistral OCR 也都走這條路。
- 結構資訊會流失:標題層級、表格、清單,如果抽成純文字一視同仁,後面檢索就少了很多線索。好的 ingestion 會保留 metadata(這段來自哪份文件、哪個章節、哪一頁)。
- 更新從哪來:文件是會改的。你是每天全量重建,還是只處理異動(增量)?production 一定要想清楚,不然要嘛資料過期,要嘛每次重算燒爆。
這一步我的建議是:先別追求華麗,先把 metadata 留好。因為下游的權限過濾(第 5 篇)和來源引用,全都靠這些 metadata。
先給一個讓你清醒的數字:有預估指出到 2026 年,約 80% 的企業 RAG 專案會踩坑,主因不是模型不夠強,是資料品質。治理良好的知識庫,檢索準確率落在 85~92%;同一套系統,知識庫沒治理好,會掉到 45~60%。RAG 的成敗,從文件進來的那一刻就決定了一大半。
第二步:Chunking,整條 pipeline 最被低估的一步
文件不能整篇丟進去 embedding——太長、而且會稀釋語意。要切成一塊一塊(chunk)。怎麼切,直接決定檢索準不準。
最天真的做法是「每 500 字切一刀」。問題是它會從句子中間、甚至從一個概念中間切斷,檢索回來半句話,模型看了也拼不回原意。
實務上的取捨:
- Chunk 太大:一塊塞太多主題,檢索時語意被平均掉,撈回來夾帶一堆無關內容,也更貴。
- Chunk 太小:語意完整但上下文不足,「它」「這個」指的是什麼都不知道了。
- Overlap(重疊):相鄰 chunk 重疊一小段,避免剛好切斷的概念兩邊都接不上。代價是儲存和檢索量變大。
- 語意切分 / 結構切分:照標題、段落、語意邊界切,而不是照字數硬切。但別把它當銀彈——2026 好幾組 benchmark 反而打臉它:有人在學術論文上跑七種策略,最樸素的 recursive 512-token 固定長度切分以約 69% 準確率拿第一,某些語意切分反而掉到 54%,因為它切出一堆平均才 43 token 的碎片。所以務實的順序是:先用 recursive 固定長度(如 512 token)當穩健基準,只有當 eval 證明值得,才升級到語意 / 結構切分。重點從「挑一個神奇的 chunk size」變成「偵測並尊重這份語料的原生結構」——法規的條款邊界、程式碼的 function 區塊、技術手冊的章節層級。
沒有一組「最佳 chunk 參數」適用所有資料。技術手冊、對話紀錄、法規條文,最佳切法都不一樣。這就是為什麼你需要 eval(第 9 篇)——chunk 策略要用一組黃金問題去量,而不是憑感覺。
第三步:Embedding,把語意變成座標
每個 chunk 丟進 embedding 模型,變成一個向量(一串數字),意思相近的內容,向量距離也相近。使用者的問題也變成向量,然後在向量空間裡找最近的幾個 chunk。
這步的選擇(embedding 模型、維度、要不要 hybrid search)牽涉很多取捨,我放到下一篇(第 4 篇)整篇細談,因為它跟向量庫的選型是綁在一起的。這裡先知道:embedding 模型一旦選定、資料一旦向量化,之後要換模型=整庫重算,所以這是個要慎重的決定,不是隨手挑一個。
第四步:檢索與 reranking,兩段式才準
檢索 top-k 個最相近的 chunk,是基本動作。但「向量最相近」不等於「對回答最有用」。所以成熟的 RAG 會做兩段:
- 粗檢索(recall 優先):先撈回比較多的候選,比如 top-20。寧可多撈,先別漏。
- Reranking(precision 優先):用一個更精準(但更貴)的 reranker 模型,把這 20 個重新排序,挑出真正最相關的 top-3~5 才餵給 LLM。
為什麼要分兩段?因為直接 embedding 相似度有它的盲區(比如同義不同詞、或字面像但語意反)。Reranker 看的是「問題和這段文字的相關性」,通常明顯更準。代價是多一次模型呼叫——又是一個延遲 / 成本 / 品質的取捨(第 10 篇的主題)。
補一句可以直接動手的:這個 reranker 通常就是一個 cross-encoder——把問題和候選段落一起餵進模型做 full attention、直接吐出相關性分數;對照之下,粗檢索那段用的是 bi-encoder(query 和文件各自先變向量再比距離),快但較粗。要選型的話,省錢、資料不外送就用開源的 bge-reranker-v2-m3(多語),要託管 API 就 Cohere Rerank。實測上 cross-encoder 在一般 RAG 能帶來 NDCG 約 +5~15 分、字面困難的資料集甚至更多,額外延遲常壓在 200ms 內。候選撈多少?top-20 是合理下限,很多 production 會撈到 top-50~100 再收斂。
另一個 production 常見的強化是 hybrid search:把向量檢索(語意)和關鍵字檢索(BM25,字面)合起來。當使用者問題裡有專有名詞、料號、錯誤碼這種「字面必須精準命中」的東西,純語意檢索反而會漏,關鍵字這時候救場。
在 2026 的企業場景,hybrid 其實已經接近預設配置,而不只是「強化」。但兩路結果怎麼合?別自己土法加權——向量分數和關鍵字分數的尺度根本不可比。事實標準是 Reciprocal Rank Fusion(RRF):它用「排名」而不是「分數」運作,繞開了兩邊分數對不齊的校準問題,預設 k=60、每路先撈 20 筆是穩健起手式。一個要先打的預防針:留意你用的引擎是不是真的在跑 BM25——Postgres 原生的 tsvector 其實不是(第 4 篇細談)。
第五步:生成,而且一定要附來源
最後把檢索到的 chunk 組成 context,連同問題一起餵給 LLM 生成答案。看起來這步最簡單,但企業版和玩具版的差別,全在這一步的兩個要求:
1. Source citation(來源引用)——這是信任的門檻
答案不能只給結論,要能指回「這句話是根據哪份文件、哪一段」。原因很現實:
- 使用者可以自己驗證,不用盲信 AI。
- 出錯時可以追責、可以修——是文件本身錯了,還是檢索撈錯了。
- 它逼著模型把話收斂在證據裡,而不是天馬行空。
我會說得更重一點:沒有來源引用的企業 RAG,不該上 production。因為你等於要求業務、工程師、主管去相信一個無法驗證的黑盒。第一次它唬爛被抓到,整套系統的信任就崩了。
但這裡要誠實補一刀:引用是必要、但不充分。2026 的研究把這件事拆得很細——「引用正確」不等於「答案真的從證據推導出來」。模型常常先用腦袋裡的記憶把答案生出來,再回頭去檢索段落裡撈幾句看起來支持的話貼上去(post-hoc citation),引用乍看都對,實際上答案根本不是從那段證據長出來的。這叫 grounding 的假象,光靠引用擋不住。所以 2026 的信任架構是四層、不是一層:維護良好的知識庫 → grounding → 每句可追溯的 citation → span-level 驗證(在答案送到使用者前,逐句檢查每個 claim 是不是真有檢索證據撐著,撐不住的就標出來)。這正好接回第 1 篇的鴻溝一:能附來源 ≠ 能信任,中間還隔著一層驗證。
2. Grounding 與「不知道就說不知道」
要在 prompt 和系統設計上明確要求:只根據檢索到的內容回答;檢索不到依據,就老實說找不到,不要自己編。
這對抗的就是第 1 篇講的鴻溝一(幻覺)。一個好的企業 RAG,寧可說「這個問題我在現有文件裡找不到明確答案,以下是最相關的幾份文件給你參考」,也不要自信地掰一個聽起來很對的答案。降級成「我幫你找到線索」,比硬給錯答案安全得多。
最常見的五個翻車點(直接給你對照)
- Chunk 切爛:檢索回來的片段語意不完整 → 調 chunking 策略、加 overlap、改語意切分。
- 檢索撈不到 / 撈錯:純向量的盲區 → 加 hybrid search、加 reranking。
- 答案不附來源:使用者無法驗證、信任崩盤 → 從 ingestion 就把 metadata 留好,生成時強制引用。
- 資料過期:文件改了庫沒更新 → 設計增量 ingestion 與更新策略。
- 沒有 eval:改了參數不知變好變壞 → 建黃金題庫做回歸(第 9 篇)。
小結
RAG 的精髓不是「接得起來」,是這條 pipeline 的每一步——ingestion 留好 metadata、chunking 不切爛語意、檢索做兩段、生成一定附來源——全部到位,它才會從一個「會唬爛的問答玩具」,變成一個「業務敢拿來查、查錯還能追」的企業系統。
下一篇,我們往這條 pipeline 的地基挖:向量資料庫到底要不要上專用的,還是 PostgreSQL 加個 pgvector 就夠?embedding 模型怎麼選? 這是會直接影響你成本和延遲的選型題。
文章簡報










延伸閱讀
- 上一篇:企業 AI Agent 系統架構藍圖
- 用 Cloudflare Vectorize 與 AI Gateway 打造 RAG——一個具體的 serverless RAG 實作參考
- 下一篇:《向量資料庫與 embedding 策略:pgvector vs 專用向量庫》